JILT 1999 (1) - Osborn & Sterling
Automated Concept Identification within Legal Cases
A legal knowledge based system called JUSTICE is presented which can identify heterogeneous representations of concepts across all major Australian jurisdictions, and some concepts within US and UK cases. The knowledge representation scheme used for legal and common sense concepts is inspired by human processes for the identification of concepts and the expected order and location of concepts. These are supported by flexible search functions and various string utilities. JUSTICE is a client-based legal software agent which works with both plaintext and HTML representations of legal cases over file systems, and the World Wide Web. In creating JUSTICE an ontology for legal cases was developed, and this is implicit within JUSTICE. The ontology is a formalisation of an idealised but backwardly compatible conceptualisation of knowledge within legal case headnotes. The benefits of adopting such an ontology include providing the same functionality as JUSTICE. The identification of concepts within data is shown to be a process enabling conceptual information retrieval and search, conceptualised summarisation, automated statistical analysis, and the conversion of informal documents into formalised semi-structured representations. JUSTICE was tested on the precision, recall and usefulness of its concept identifications; achieving good results. The results show the promise of the approach and establish JUSTICE as an intelligent legal research aid offering improved multifaceted access to the concepts within legal cases. Keywords : Intelligent law information systems, Intelligent research aid, Conceptual information retrieval, Legal WWW agent, Legal Knowledge Representation, Legal Ontology, Formalising Law This is a Refereed Article published on 26 February 1999. Citation: Osborn J et al, 'Automated Concept Identification within Legal Cases',1999 (1)The Journal of Information, Law and Technology (JILT). <http://elj.warwick.ac.uk/jilt/99-1/osborn.html>. New citation as at 1/1/04: <http://www2.warwick.ac.uk/fac/soc/law/elj/jilt/1999_1/osborn/> Consider a person involved in a court action who is concerned with how the judges are likely to rule. Perhaps the person is appealing a personal injury case and wants to know when in the past the judges have found for the appellant. This information may provide an insight into how the judges make decisions, which can be used to evaluate chances of success, and guide tactics and strategies for preparing the case. How could a person find this information? A knowledgeable lawyer could give vague indications, but would require thorough research for definite answers. This may lead the person (or their lawyer) to one of the many digital collections of case law, to try a boolean query like: ['Personal Injury' AND (<Name of Judge> OR <Name of Judge> OR <Name of Judge>)] This would generate a large listing of cases[ 1], which would suffer from the ubiquitous too many problem[ 2] of search engines. Nevertheless, every case would need to be examined by a human with domain knowledge and divided into wins and losses. This time consuming and difficult task cannot currently be performed by any available legal search engine because they only offer word matching, not concept matching. This is an instance of a much broader problem than just the retrieval of desired legal cases. Briefly stated, the problem is that current search engine technology does not adequately address queries for abstract concepts which have heterogeneous representations. Examples of such representations could include the problem of extracting all the five star movies on a critic's Web site, or all the recipes from a cook's travelogue, or the winners in a legal cases. Most search engines and tools use standard lexical information retrieval techniques with some heuristics, e.g. giving a match near the top of a document a higher score or using synonym expansion on search terms. A paradigm shift toward semantics is needed so researchers can treat information collections as they would an expert human user who had fully processed and remembered that same collection. This research is an attempt to bridge the gap between current syntax methods and concept identification[ 3] which is required to answer conceptual questions like the one above. The research was motivated by a desire to provide legal researchers with a tool which would provide conceptual based searching of case law. The initial insight was a belief that a knowledge based approach to extracting legal concepts would perform well in the domain of legal cases. The choice of methodology was primarily influenced by the desire to obtain the best quality tool. JUSTICE is the name of the tool created, and is an acronym for A Judicial Search Tool using Intelligent Concept Extraction. JUSTICE is able to recognise and extract abstract legal concepts from heterogenous digital representations of legal cases. The ability to recognise concepts enables many functions including: conceptual searching and summarisation; the collection of statistics across concepts; and the ability to convert informal documents to formalised representations, eg HTML to XML. JUSTICE can identify twenty two concepts, with high levels of accuracy; correctly extracting an average of 97.1% of concepts across HTML and plaintext representations of all major Australian jurisdictions. JUSTICE is superior to related work in both the variety of data with which it can work and the levels of accuracy achieved. Some of the questions or commands possible with JUSTICE include:
Enabling JUSTICE to answer such questions involved giving it knowledge of an ontology for legal cases. Although JUSTICE only understands part of all possible concepts in legal cases, all the possible concepts were formalised into an ontology for Australian legal cases. This is presented as both a directed graph and as an XML ontology. It is believed to be the first of its kind for Australian law, and is well compared with developments around the world. Extracting abstract concepts is often difficult because the required information is not stored in a structured manner and instances of the concepts are not explicitly recorded within the system as part of an abstract concept. One way of achieving concept based searching would be to force the originators of the data to adhere to a shared ontology. An ontology is a formalised specification of the conceptualisation of knowledge within a domain (Bench-Capon T et al, (1997)). Adherence to an ontology would make conceptual searches within that ontology trivial. It is an argument of this paper that to enable semantic querying, concepts should be marked up during the creation process. Initial effort invested during creation will reduce the difficulty of the task later and provide higher levels of accuracy. Of course there is a limit to the amount of effort the creators of cases will expend, and for this reason such formalism should initially be restricted to the headnotes of cases. Once an agreed ontology is in existence, a form can be created which the author must complete. When the case is exported (i.e. distributed and published) a simple program can be used to delimit each field of the form with the correct meta-tag. Legacy data cannot be dealt with as easily and will require an automated concept identifier, like JUSTICE. This paper is structured as follows. Section 2 outlines the domain within which JUSTICE works, including both concepts and legal cases. Section 3 discusses the currently available tools, and points to future developments including a formalised ontology for legal cases. Section 4 outlines the methodology used to create JUSTICE, and the knowledge representation scheme employed. Section 5 presents the architecture of the system. Section 6 shows the results and discussion and section 7 presents the conclusion. A concept is defined by the Oxford English Dictionary as a general notion or an abstract idea or an idea or mental picture of a group or class of objects. The ability to completely capture an informal abstract idea within a fixed precise definition is generally regarded as impossible; a more useful view is that instances of a concept are better described as having a family resemblance[ 4]. This has implications for knowledge based systems which often try to define every possible instance of a concept with inflexible rules. The approach of adding more and more heuristics to increase recognition of all instances of a concept is ultimately flawed in most domains. This limitation of the methodology was accepted for the current research because of a belief that such methods would capture enough concept instances in the legal domain to be useful. Identifying those instances which fall between the rules requires methods other than pure knowledge based approaches. A legal case is composed of two significant parts[ 5], the headnote and judgment (of which there may be more than one). JUSTICE focuses mainly on the headnote of a judgment. The headnote of a case provides a summary of aspects of the case. The type of concepts which appear in the headnote are sufficiently interesting to be of great use to legal researchers. Paper law report headnotes contain human summaries of facts and law, but these do not appear in the digital counterparts. Some of the concepts possible in digital headnotes include: case name, parties, citation, judgment date, hearing date, judges, representation (i.e. lawyers), and law cited. The judgment of a case is examined for case segmentation, the order concept and the winner/loser concept. The headnote is that part of a case which is likely to be further formalised by the courts, and so is the most likely aspect to benefit from a formal ontology. We hope that this work encourages the beginnings of such a project. It is hoped that once the benefits of identifying headnote concepts are known a move toward further formalisation will be encouraged. Extracting concepts from headnotes is a difficult problem because of the varied representations created through the currently ad-hoc process of headnote creation. Headnotes can differ across years, courts, judges, and headnote authors. JUSTICE can extract twenty-two concepts from a case. JUSTICE records both the start and stop location of each concept, along with the concept content or the text which set an abstract concept. The start and stop markers are needed to enable accurate concept identification, and to allow for the conversion of syntax-based documents (e.g. plaintext or HTML) into semantically segmented documents, e.g. XML. Some concepts are subsidiary or are used to segment a case into its components, e.g. start of judgment, and are not usefully used within a search. The complexity of each concept differs greatly, the simplest concept identification uses two heuristics, the most complicated twenty six. The choice of concepts was determined by two factors. The research aimed to produce a useful tool for legal researchers and this desire conditioned that the concepts be useful ones which may be searched upon but also concepts which could be identified with high rates of accuracy. The ontology for legal cases identified 76 concepts, which future versions of JUSTICE will be able to identify. The concepts which are identified by JUSTICE and usefully searched on include: headnote, heading section, case name, court name, division, registry, parties (initiator and answerer), judge, judgment date, citation, order, and winner/loser. The definitions of the concepts identified are mostly obvious, the winner/loser concept however requires some explanation. Analysing legal cases in terms of winning and losing can be inappropriate; further such a distinction does not neatly divide cases. Cases with complex orders, multi-party cases with different orders for each party and single party cases are all difficult to analyse with the concept of winner/loser. Nevertheless lawyers often talk of winners and losers and such a conceptual distinction has real value especially when the interest is law and not practicalities. JUSTICE defines winning, as winning the judgment, i.e. the court rules in that party's favour. JUSTICE returns one of four answers when locating winner/loser: a) The Initiator won. This includes the plaintiff, applicants, appellants, prosecution etc. b) The Answerer won. This includes the respondent, the defendant, defence etc. c) There was no clear decision in this case. This means that no decision could be found, either in summary form or as free text in a part of the judgment. d) There was no clear winner in this case. This means that a decision was found but no clear winner was apparent and could be interpreted such that either party could have won. Current legal information retrieval tools have not changed much since the 1960s. Perhaps the most obvious change is increased availability of the document collections and the large increase in the amount of data available. A move toward semantics was fairly obvious from an early stage, but developments toward this goal have been slow in arriving. Queries on document collections can be classified in two ways: 1) The range of document segments of instances of a document collection, e.g. cases, which may be searched; and 2) The type of search available, e.g. ranked or boolean. Most document collections are divided into jurisdictions so searches can be limited or listed according to their source. Full text searches have been around the longest, while more recent document collections offer finer grained searches, including at least title. Common fields include citation and court. Proprietary CD-ROMS (Butterworths) offer some of the best segmented searches, with some including judge and representation. TheSCALEplussystem provides segmented search but the usefulness of this is undermined by the unreliability and inaccuracy of the segments. Legal researchers demand high levels of accuracy. Any system which is expected to be useful must be complete and able to be trusted by the researcher. This requirement is more important for legal document collections than for other document collections. If such accuracy is not available the system will not be used. The flexibility of search methods is increasing, e.g. additional operators like near or same paragraph, but most still rely upon lexical matching which limits the type of search available to the user. Two closely related current projects deserve special mention: The Supreme Court of Canada SGML project (Poulin D et al, (1997)) SALOMON (Moens M-F et al, (1997)) There are two possible approaches to concept identification. The first approach is to use a tool such as JUSTICE which can identify concepts within cases to process collections of cases and record the identified concepts. The other approach is applied when the context is created (ie a legal case is written), the concepts can be identified within a self-describing format. The benefits of this approach are extremely high levels of accuracy, but such a process would require standardisation across case writers and courts. Segmentation of cases is useful and is equivalent to concept identification for simple concepts. More complicated concepts require more sophisticated identification, for example, even if a summary order is available and can be searched, the winner/loser concept cannot be located by a syntax search. As stated above one way of creating conceptual information retrieval is to get judges to use formal methods to record their judgments. Although this method would be highly effective it is unlikely that judges would adopt such measures. More probable is convincing headnote authors to increase the use of formalisms when they create headnotes. It is hoped that the presented ontology will encourage such a move. Full conceptual information retrieval would provide new multifaceted access to data. It would provide conceptual searching which would close the gap between human mental queries and current syntax approach and allow for statistical results to be gathered across concepts. Legal researchers could get better information and collect profiles across any concept or collection of concepts. This would provide new information to the community, e.g. the average time it takes a particular judge to deliver a judgment, and may affect the way lawyers argue or present a case, e.g. if a judge shows a pattern of following another judge's judicial reasoning. The World Wide Web exploded with HTML largely by accident, and the suddenness of this explosion meant that the best technology was not used. The Web was always going to move in the direction of semantics, and XML is likely to be the representation format. XML will greatly improve the depth and quality of digital collections of human knowledge and gossip on the web. Data will be more accessible, and a paradigm shift, away from format onto semantics will be encouraged. Intelligent search engines will emerge, browsers will understand documents, and web agents will add value to data in truly amazing ways. Predicting time frames for change is largely guesswork, some people had predicted the completed XML transformation of the entire web by mid-1997. It is now apparent that the conversion of data from HTML to XML will be a long and gradual process. Future tools will provide semantic templates which allow documents to be saved in XML marked up format. This will be enabled by common semantic ontologies, and streamlined by the use of forms to aid data entry. These will work for newly created data, but legacy data (i.e. plaintext and HTML) must be analysed and the concepts identified. Concept identification is the process required to convert such documents into semantically marked up collections. Cases can be segmented and more abstract concepts can be contained within tags. JUSTICE is able to do this for some concepts within legal cases. JUSTICE is currently an agent based system, and such systems have serious shortfalls for large document collections in that they do not provide real-time results[ 8]. The same technology however, could be used to create an XMLised collection of legal cases and then an XML aware search engine could be used to provide the same set of answers as JUSTICE, and enable statistical queries, but in real-time. 3.1.2 Legal Case Ontology - LegalCase.dtd While creating JUSTICE the existence and interrelationships between concepts in a judgment was necessarily explored. This knowledge was formalised as an ontology. An ontology is an explicit specification of a conceptualisation of a domain. (Bench-Capon T et al, (1997)) This ontology was created using a process known as ontological engineering, all the concepts which appear within cases and other useful additional concepts are collected by examining many cases. When creating the current ontology, a goal was to make it reusable, that is able to be used in more than just one jurisdiction. The role of an ontology is to provide a framework on which the concept instances within a domain can be structured, and access to the information is improved. The real value of ontologies appear when a single ontology becomes a standard within a domain. This makes knowledge sharing effective and will increase the richness of digital legal tools. It is hoped that the need for such a case law ontology is clear and that the DTD presented here encourages the adoption of a DTD for legal cases. Accurate concept identification in complicated domains requires knowledge of an ontology. This makes concept identification more accurate and allows inter-conceptual relations to be used for integrity checking. JUSTICE has an implicit knowledge of part of an ontology which was created to cover legal cases with British heritage. This ontology was formalised, as a graph and as an XML DTD and is available fromhttp://www.cs.mu.oz.au/~osborn/. LegalCase.dtd consists of seventy six concepts most of which cover possible concepts within headnotes; it provides compatibility with past cases and allows for useful new concepts to be included. The concepts mapped within judgments are limited to facts, law and order[ 9]. The DTD makes the concepts explicit and shows the complex web of interrelationships between them. JUSTICE does not yet contain knowledge of the entire ontology. To maximise the usefulness of the DTD, a low level of granularity was chosen; the only reason to stop at a particular level is a question of the usefulness of continuing to expand a concept. Fine grained definitions like Person, Date and Citation allow for flexible and useful searches and interesting (and controversial) statistical querying; eg Compare all male Judges awarding to a Female Initiators, vs a Male Initiators. JUSTICE provides a useful search tool, but it is hoped that a formalised ontology will be adopted by headnote authors and be used to explicitly represent concepts within legal cases. The conversion of legacy cases, i.e. plaintext and HTML, to semantic representations can be achieved using a tool which identifies concepts within documents and has a knowledge on the applicable ontology. The tool can insert appropriate tags at start and stop locations of simple concepts or encode more complicated concepts within stand-alone tags. A knowledge based approach was used to capture domain knowledge. The choice of methodology was guided by a desire to create a useful tool. Each concept is described by multiple heuristics. Drawing from experts systems and good software engineering practice the rules are stored separately from the processing elements (Stefik M (1995)). This allows heuristics to be easily changed or added, so adding non-Australian domains would be possible within the current architecture. Although a knowledge based approach has limitations, particularly instances falling between the spaces of formalised rules; it has proved to be a very useful approach. JUSTICE provides support for the proposition that a knowledge based approach is useful in semi-structured domains. Legal domain expertise was relied upon to create rules which described the concepts. The processes which humans may use to perform the task of extracting concepts from text were considered and four ideas surfaced and guided development: 1) The expectation of information, and graded loosening of a filter; The knowledge engineering task involved examining hundreds of cases and trying to write down the rules which could be used to describe the concepts. The descriptions were constrained to using what emerged as a useful set of descriptors. The rules consist of collections of primitives which define each concept. For example, one rule for the case name expert is: after(caseName, startheadnote) & whitespace 'v' whitespace, where & is a logical or and is the concatenation operator. There are many types of knowledge representation schemes possible, both generic varieties and legally specific. The available languages did not meet our specific needs and so a purpose-built language was developed. The knowledge representation used was a set of primitives which emerged from the knowledge engineering process as useful descriptors of the domain. The set of primitives were collected into separate components of the architecture; these were not domain specific but were used to create domain specific heuristics. The custom KR scheme consists of three components: 1) Graphical description language (the Viewer class) The set of primitives works with both HTML and plaintext. The architecture is such that changes in HTML can easily be incorporated into the system. Dealing with HTML is often difficult because HTML is a very unreliable markup language. Tags such as <B>Supreme </B><B>Court</B> are not uncommon, especially where the text has been automatically marked up. A simple approach of stripping all tags results in useful information being lost and prevents concept positions from matching up with the original HTML source. For this reason many heuristics use the primitive find, which locates strings with regard to how they appear to a viewer not just on straight syntax matching. 2) Expected Concept Locations (the Case class) The primitives allowed when specifying position include (where X and Y are integers marking a place in the document, and X is usually the start or end of a concept): after(X,Y), before(X,Y), between(X,Y,Z), concept(X,NUM), nearEnd(X), nearStart(X), next(X,Y), prev(X,Y), within(X,Y). 3) String Utilities
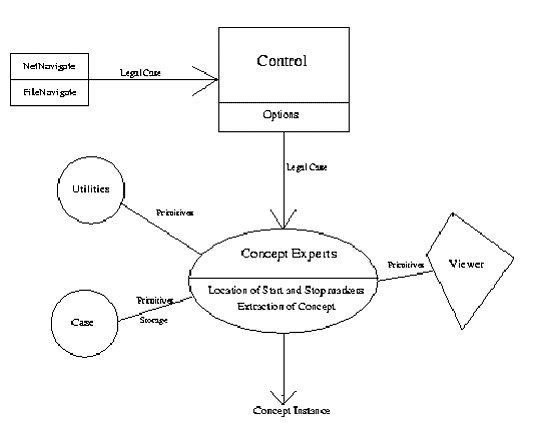
Figure 5.1: The Architecture and Control Flow of JUSTICE As can be seen from figure 5.1, JUSTICE consists of several interrelated classes:
JUSTICE works on plaintext and HTML represented cases. It is entirely written in Java 1.1 and operates over a TCP/IP network, or file system. The user simply interacts with the GUI to select the desired options. JUSTICE currently allows searching and summarisation over concepts. Cases can be processed individually or in batch mode over files and directories. Statistical queries are available but are not as yet fully automated. Each concept is described by a collection of rules. These rules were created during the knowledge engineering process and consist of collections of primitives permitted by the system. Rules within collections of rules are ranked according to three schemes, a) appropriateness given known data; b) heuristics relating to most likely position, and c) a relative ranking scheme. These schemes provide resolution if more than one rule fires, and improve the accuracy of results. Evaluating concept identification tools is a difficult task. Comparisons between tools are difficult because of differences in the structures of domains and the difficulty of comparing the different concepts identified. Further testing the results of such tools is a human and hence time-consuming process. An obvious approach is to utilise the traditional measures of information retrieval, namely precision and recall. These measures must be slightly altered (Moens M-F et al, (1997)), with precision and recall defined respectively as the proportion of correct responses over the number of responses the tool returned, and the proportion of correct responses over the number of responses a human expert would return. Precision measures the degree of accuracy and any errors in the returned concepts; and recall measures the degree of completeness and any errors by reason of missing concepts. The precision and recall statistics were collected using very strict measure of correctness. The summarisation feature of JUSTICE was used to output a listing of results over the test set of cases and then one of the authors intellectually identified the concepts within the same set of cases and compared the results. If a correct concept was identified by JUSTICE but extraneous data was also returned, e.g. a bracket, then the extraction would be recorded as incorrect. An additional metric, useable, was included to better record the usefulness of extractions. The criteria for useable correctness, was whether the extracted concept would be returned if the JUSTICE search feature, which uses substring matching was used to search for the correct concept. That is, useable counts extraction with extraneous data as correct. The usefulness of precision/recall metrics for concept extraction tools is worthy of separate research; but was incidental to the current work. As can be seen from the results the precision and recall results statistics were often the same. This occurred because most concepts are in every case, and JUSTICE returns an answer for every case. JUSTICE was assessed as a legal research tool, so many of the concepts which it identifies were not directly assessed, but the assessed concepts depend upon the accurate identification of the other concepts, e.g. most concepts depend on an accurate identification of the headnote start and stop concept. The testing included testing over heterogeneous data from heterogeneous sources. JUSTICE was tested with randomly chosen and previously unseen data. Given the small test sets of the non-Australian and plaintext cases the HTML Australian results are the best indicator of the performance of JUSTICE. The index to the results table is: HS: Heading Section; P: Parties; Date: Judgment Date; Cite: Citation; Court; Div: Division; Reg: Registry; Judge; WL: Winner/Loser. The Australian data was taken fromAustlIIandSCALEplus. The HTML test data consisted of 100 cases taken from all the major Australian jurisdictions available.
Across concepts these results are: Precision: 96.3% The plaintext data test set consisted of 20 randomly selected cases.
Precision: 90% JUSTICE was designed to work on Australian cases but given the similarities between case law descendent from British law, it was interesting to trial JUSTICE on such cases. Results on US and UK data before domain specific adjustments were limited to four concepts: the Heading Section, the Parties, Court and Judges. Twenty US cases were taken fromFindlaw,
Precision: 32.5% Fifteen UK cases were taken from two sites[ 10].
Precision: 29.1% Formal testing pointed to shortfalls within the heuristics which show the need for further refinement of the knowledge base. Formulating heuristics is an iterative process, so it was not surprising that the heuristics were not fully optimised. After examining the causes of the errors, it is believed that all concepts except the winner/loser one could be increased to very high levels of accuracy. The results for the winner/loser concept on the Australian cases deserve discussion. The level of accuracy for this concept is lower than the others, but the results are more complicated. Only one of the errors was the opposite of the correct answer, the other errors were either returning no clear decision or no clear winner. Dividing cases with the winner/loser is often a difficult task even for human experts, so lower accuracy than the others is to be expected. JUSTICE accurately determines if a case has no winner or loser with high levels of accuracy. Most of the errors involve JUSTICE reporting no decision where an expert after examining the case can determine a winner. That being said, there is often some subjectivity in determining a winner. With fine tuning of the heuristics it is believed that accuracy rates can be improved, but accuracy is not expected to match the very high levels many of the other concepts could reach. Results from the plaintext data are lower than the HTML data. This is to be expected as plaintext data carries much less information about the nature of its text within it. JUSTICE performed relatively badly on non-Australian cases. This is not surprising given that no effort was made to customise concept descriptions to those domains, and that concepts have quite different representations, e.g. in UK House of Lords cases, judges are called Lords. The results also show a weakness in a knowledge based approach, namely the need to customise the knowledge base for each different domain. Testing highlighted the fact that more inter-conceptual checking could aid in the detection of errors. In addition, using such checks enables a single agent to work over different domains, either different courts or different countries. Very few errors were such that a human expert viewing the output would not recognise them as errors, eg the wrong court being returned. This result shows that if JUSTICE returns a definite answer it is highly probable that it is correct. JUSTICE coupled with an expert can therefore provide very accurate answers and avoid false positives. Broadly the results suggest that JUSTICE should be less reliant on expecting accurate data, eg matching brackets; and that HTML allows for greater precision in the extraction of concepts. We believe that JUSTICE has substantially shown the usefulness of its approach; however there are many improvements which could be made, to make JUSTICE a more useful tool. The addition of new concepts and providing a means to allow non-programmers to extend JUSTICE, are important advances. These would have to be combined with the automated reconfiguration of the interface. Future extensions will include the complete mapping of all concepts possible in the ontology to rules within JUSTICE. Some complex concepts can be found within the judgments of cases. Extensions of JUSTICE could incorporate statistical methods for extracting these concepts from the full text of cases. Improving the performance of JUSTICE on non-Australian cases will require investigating the concept representations in the data, and expressing them using the primitives provided by JUSTICE, and inserting these into the elements in each concept experts' heuristic array. It is important to note that the work needed to extend JUSTICE to at least the US and UK courts (and quite likely many other courts with UK heritage) will not require changes to the architecture of JUSTICE, and could be done relatively quickly once the correct heuristics were deduced. It should be possible to provide a future version of JUSTICE which could operate over many different domains with the same set of heuristics, using ranking schemes and jurisdiction identifiers to isolate the most useful heuristics. JUSTICE is a useful legal research tool providing previously unavailable concept based searching, summarisation and statistical compilation over collections of legal cases. The implementation required the identification of an ontology for legal cases which has been formalised. This is believed to be the first of its kind for Australian legal cases. The results of JUSTICE have extended previous research by increasing accuracy while also extracting concepts from heterogenous domains. Further the identification of concepts within data has been shown to be the technique required to enable concept based searching, summarisation, automated statistical collection and the conversion of informal semi-structured plaintext and HTML into formalised semi-structured representations. As a prototype system, JUSTICE and LegalCase.dtd provide a sound basis on which to encourage and extend efforts to increase the richness of access to legal information. It is hoped that a settled legal ontology will become commonplace for legal cases, and that headnote authors will use such a formalism during the creation stage of headnotes, while previous decisions not using such an ontology can be converted using JUSTICE. Until this situation arises JUSTICE can be used by researchers to enable concept based searching, summarisation and statistical information gathering from legal cases. Bench-Capon T and Visser P (1997) Ontologies in Legal Information Systems; The need for Explicit Specifications of Domain Conceptualisations, Proceedings of the Sixth International Conference on Artificial Intelligence and Law, (p 132). Butterworths CD-ROM containing limited unreported judgments from senior Australian Courts. Moens M-F, Uyttendaele C and Dumortier J (1997) Abstracting of Legal Cases: The SALOMON Experience, Proceedings of the Sixth International Conference on Artificial Intelligence and Law, (p 114). Poulin D, Huard G and Lavoie A (1997) The other formalisation of Law: SGML modelling and tagging, Proceedings of the Sixth International Conference on Artificial Intelligence and Law, (p 82). http://www.droit.umontreal.ca/doc/csc-scc/en/index/permission.html Stefik M (1995) Introduction to Knowledge Systems, Morgan Kaufmann Publishers, San Francisco[17] Bing J (1987) Designing Text Retrieval Systems for Conceptual Searching, Proceedings of the First International Conference on Artificial Intelligence and Law, (p 43). Bing J (1989) The Law of the Books and the Law of the Files - Possibilities and Probabilities of Legal Information Systems, In Vandenberghe G, Advanced Topics of Law and Information Technology (p 151), Kluwer, The Netherlands. Bray J Beyond HTML: XML and automated web processing,http://developer.netscape.com/viewsource/bray_xml.html, copied Nov 1998. Daniels J and Rissland E (1997). Finding Legally Relevant Passages in Case Opinions, Proceedings of the Sixth International Conference on Artificial Intelligence and Law, (p 39). Dick J (1987) Conceptual Retrieval and Case Law, Proceedings of the First International Conference on Artificial Intelligence and Law, (p 106). Greenleaf G et al (1997) The AustLII Papers - New Directions in Law via the Internet, The Journal of Information, Law and Technology (JILT) (2). < http://www2.warwick.ac.uk/fac/soc/law/elj/jilt/1997_2/greeleaf/ >Hafner C (1987) Conceptual Organization of Case Law Knowledge Bases, Proceedings of the First International Conference on Artificial Intelligence and Law, (p 35). van Noortwijk K and De Mulder R (1997) The Similarity of Text Documents, Journal of Information, Law and Technology (JILT) 2. http://www2.warwick.ac.uk/fac/soc/law/elj/jilt/1997_2/noortwijk/ Sterling L (1997) On Finding Needles in WWW Haystacks, Proceedings of the 10th Australian Joint Conference on Artificial Intelligence: Advanced Topics in Artificial Intelligence, (p 25). Zeleznikow J & Hunter D (1994) Building Intelligent Legal Information Systems. Kluwer Law and Taxation Publishers, Deventer, The Netherlands. Australasian Legal Information Institute (AustlII):http://www.austlii.edu.au Findlaw:http://www.findlaw.com Osborn J, LegalCase.dtd:http://www.cs.mu.oz.au/~osborn SCALEplus (The legal information retrieval system owned by the Australian Attorney General's Department):http://SCALEplus.law.gov.au/ Footnotes 1A case law only search onAustlIIwith: (Personal Injury) AND (Deane OR Mason OR Brennan) returned 881 hits. 2Where many of the hits would be unrelated to the desired query; eg cases where the judge's name happened to be in the text but not as a judge, or the search engine used various extending heuristics to widen the scope of hits, eg stemming or synonym extensions. 3Throughout this paper, the terms concept identification and concept extraction are used interchangeably. 4Wittgenstein, L. (1968) Philosophical investigations, Blackwell, London. 5Sometimes a third part, an Endnote, occurs which may contain a summary order and a certification by the associate of the authenticity of paper judgments. 6Moens M-F et al(1997) at page 116. 7This is calculated by averaging case and segment category, alleged offences and opinion of the court using the stricter legal evaluation result. Results for individual initial structuring of cases are not given, only an average across all identifications. 8JUSTICE took seventeen seconds to extract the concepts from one hundred cases (4.56 megabytes) on a file system. 9The existence of a clear distinction between facts and law is not accepted by all jurisprudential philosophy, but is a satisfactory distinction for practical purposes. 10 http://www.parliament.the-stationery-office.co.uk/pa/ld/ldjudinf.htm |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||